
La classificazione automatica dei documenti aziendali con l’AI ed il Machine Learning: come funziona e come cambia la gestione dei processi di lavoro

Cos’è la classificazione automatica dei documenti e delle informazioni
La classificazione automatica dei documenti e delle informazioni è l’operazione che consente di etichettare un documento senza bisogno di intervento umano, ma solo con l’aiuto di un algoritmo intelligente che lavora in autonomia.
Queste etichette contengono una specifica informazione riguardante i documenti, come ad esempio la loro funzione o la loro natura. Per esempio, ci dicono se il documento è una fattura, un contratto, un sinistro, e così via. Ma le etichette possono essere anche di altra natura, a seconda di chi usa il documento o di cosa vuole sapere. Per esempio, possono essere i nomi delle aziende clienti che il sistema gestisce, o dei reparti dell’azienda che lo utilizza.
I modi per implementare la classificazione automatica sono tanti, come per esempio cercare e trovare delle parole chiave all’interno del testo dei documenti.
Siav AI Classifier, la nostra soluzione per la classificazione automatica dei documenti, usa metodi di Machine Learning, che sono molto efficaci in quanto attuano la classificazione sulla base di quello che imparano dai documenti stessi.
Come il Machine Learning rivoluziona la classificazione dei documenti
Secondo la letteratura scientifica, il Machine Learning (ML) è un insieme di tecniche che permette ai computer di apprendere da soli, senza bisogno di persone che li istruiscano passo per passo. È una delle sfide più affascinanti dell’Intelligenza Artificiale, che interviene in situazioni dove vi sono dati dai quali i computer possano imparare qualcosa e, successivamente, operare in autonomia sfruttando quanto appreso.
Prima dell’avvento del Machine Learning, si usavano maggiormente sistemi basati su regole deterministiche, che funzionavano su regole deterministiche, per cui se determinate condizioni vengono verificate dal documento, vengono compiute in automatico determinate azioni. Ma scrivere queste regole è un lavoro lungo e oneroso, soggetto ad errori, soprattutto nei casi più complessi. E poi, le regole non bastano mai, perché ci sono sempre dei documenti che rappresentano delle eccezioni.
Gli algoritmi di Machine Learning, invece, imparano da tutti i documenti che hanno a disposizione, e scoprono da soli le regole che li governano. Così classificano i documenti in modo più efficace e intelligente.
Come preparare i documenti per il Machine Learning: estrazione, qualità e quantità del testo
Gli algoritmi di Machine Learning imparano a leggere e a capire i documenti. Ma per farlo bene, hanno bisogno che i documenti siano “preparati”. Per esempio, se vogliamo che un sistema sappia distinguere tra dieci tipi di documenti diversi, dobbiamo dargli degli esempi di documenti per ciascun tipo. Inoltre, per imparare bene, gli algoritmi hanno bisogno di “vedere” tanti documenti per ogni tipo: maggiore è il numero di esempi per ogni categoria, migliore sarà la capacità del modello di Machine Learning di apprendere la natura di quella categoria e di riconoscere i documenti in futuro.
I documenti possono essere di varia natura e avere svariati formati, come zip, email, PDF o altro. Ma l’algoritmo ha bisogno del solo testo contenuto in questi documenti ed è pertanto necessario usare degli strumenti che aiutino ad estrarre le parole dai file di interesse. Tra questi, ci sono anche gli strumenti di riconoscimento ottico OCR, applicati ad esempio alle scansioni.
La qualità del testo ottenuto da queste estrazioni, come ad esempio l’assenza di parole scritte erroneamente, è fondamentale per garantire la qualità dell’apprendimento dell’algoritmo di Machine Learning.
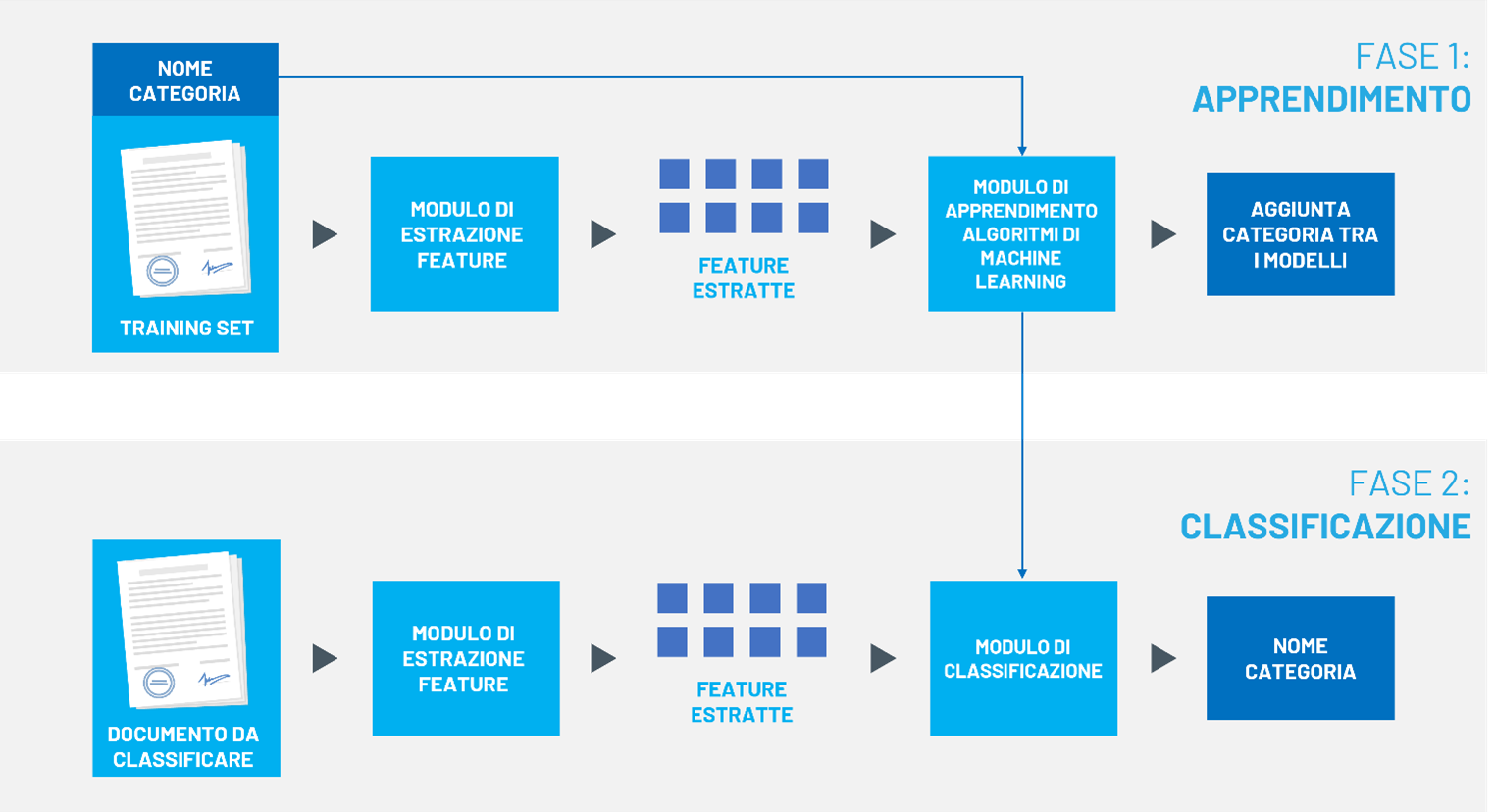
Le due fasi del Machine Learning: apprendimento e classificazione dei documenti
Un algoritmo di Machine Learning vive una prima fase di apprendimento, nella quale il sistema viene creato e prende in input gli esempi forniti, ossia coppie costituite da un documento e la sua corrispondente classe di appartenenza. Gli esempi vengono quindi elaborati da altri algoritmi e trasformati in una rappresentazione costituita da una serie di numeri, detti feature. Mentre un essere umano infatti ha bisogno che un documento sia scritto sottoforma di testo per poterlo leggere, un algoritmo richiede una diversa rappresentazione: le feature, per l’appunto. In seguito, grazie a questa rappresentazione numerica e al nome della classe del documento stesso, il sistema crea il modello. “Osservando” le coppie documento/classe di appartenenza, il modello impara a riconoscere i collegamenti tra un documento e la sua classe di appartenenza, e a riutilizzarle per future classificazioni.
Una volta che il modello è stato allenato, è pronto e può essere usato per la seconda fase di classificazione. A questo punto, si è pronti per dare come input al modello i documenti nuovi di cui non si conosce la categoria. Il modello rappresenta questi documenti sotto forma di dati, ed usa le regole che ha imparato precedentemente durante la fase di apprendimento ed individua la categoria di ogni documento.
Siav AI Classifier: la soluzione intelligente per etichettare i documenti con il Machine Learning
Siav AI Classifier sa attribuire la categoria giusta ad ogni documento in input. Ma non è solo un servizio, è anche un alleato per supportare i processi di ogni Organizzazione. E lo fa grazie a due caratteristiche fondamentali:
- è un servizio interoperabile, che dialoga senza problemi con tutte le soluzioni Siav;
- è erogato in cloud, il che permette di evitare di dover avere una infrastruttura interna per poterlo utilizzare.
Siav AI Classifier: il modello intelligente che aiuta a gestire le caselle PEC
Le caselle PEC sono spesso istituzionali, e ricevono quotidianamente una grande quantità di comunicazioni non destinate ad una persona in particolare, ma piuttosto ad un dipartimento o ufficio all’interno di una azienda. Spesso queste email vengono smistate manualmente da persone che si prendono l’incarico di leggerle e comprendere a quale altra casella interna indirizzarle. Siav AI Classifier classifica automaticamente le PEC e i suoi allegati in base al testo che contengono.
Questa operazione di smistamento automatico permette di ottenere alcuni vantaggi, tra cui:
- riduzione del carico di lavoro per chi effettua lo smistamento, che possono dedicarsi ad attività a più alto valore aggiunto;
- un inoltro rapido delle email, particolarmente utile soprattutto se richiedono delle risposte urgenti;
- evitare che messaggi riservati (destinati cioè a particolari persone all’interno dell’azienda) vengano letti da persone non autorizzate.
Nel caso di una particolare ambiguità del documento o di una classe mai vista prima nella collezione di documenti a cui è stato sottoposto il modello, si parla di messaggio residuo. Per questi messaggi può venire richiesto l’intervento di una persona che si preoccupa di classificare il messaggio a mano. Questo messaggio può poi entrare a far parte della collezione di documenti di training, che verranno usati per allenare nuovamente il modello, di modo che questi possa apprendere casi sempre nuovi e più difficili e potersene occupare correttamente nelle successive istanze.
Archiflow e AI Classifier: un esempio vincente per la GDO
Nel settore della Grande Distribuzione Organizzata (GDO) gli sconti dei fornitori sono uno strumento molto importante che permette al fornitore di rafforzare la propria posizione sul mercato, ed alle aziende clienti di ridurre le fluttuazioni della loro liquidità che avvengono in seguito ad acquisto di prodotti da rivendere. Tipicamente, dunque, un’azienda fornitrice invia all’azienda cliente una nota di credito di tipo sconto, che contiene l’ammontare dello sconto garantito. La nota verrà stornata dall’azienda cliente dal pagamento degli ordini successivi che effettuerà da quell’azienda fornitrice. Per sfruttare correttamente lo sconto, è pertanto fondamentale che l’azienda cliente gestisca la nota di credito relativa il prima possibile. E tra tutte le note di credito che si ricevono, come si può trovare quelle degli sconti in modo veloce ed efficace?
Anche in questo caso spesso vi sono persone che ricercano, tra tutte le note di credito, quelle relative a degli sconti che poi vanno a registrare. Siav AI Classifier sa distinguere le note di credito degli sconti da quelle normali, e in questo modo permette di velocizzare il lavoro delle persone.
Siav AI Classifier è già stato implementato con successo proprio in quest’ambito. La soluzione si basa su un flusso automatizzato di Archiflow che, all’arrivo di una nuova nota di credito, chiede all’AI Classifier se quella nota sia relativa ad uno sconto fornitore. In questo modo, l’utente può estrarre rapidamente da Archiflow la lista delle note di credito relative agli sconti e poterle così registrare in modo rapido ed efficiente.
Questa soluzione innovativa ha portato a una rivoluzione nella gestione dei premi fornitore: i tempi di processamento si sono ridotti di 15 volte, le risorse si sono liberate per altre attività più importanti, la liquidità di cassa si è ottimizzata e le finanze si sono concentrate sullo sviluppo del core business.
Come Siav protegge la privacy dei documenti con il Machine Learning
Oggi è sempre più importante maneggiare con cura documenti che potrebbero contenere informazioni potenzialmente sensibili e rispettare i loro vincoli di privacy. Il modello di Machine Learning entra in contatto con le informazioni contenute nei documenti in due fasi: quella di training e quella di inferenza.
Nella fase di training, i documenti vengono messi a disposizione dalle organizzazioni affinché il modello possa imparare il più possibile da casi reali. Se questi documenti avessero particolari requisiti di riservatezza, in Siav garantiamo che vengano utilizzati solo per l’allenamento del modello e non c’è modo di risalire a potenziali dati sensibili presenti nei documenti del training. Nessun dato viene salvato o trasferito al di fuori del sistema di allenamento del modello. In caso di particolari necessità, il modello può essere anche allenato direttamente sulle macchine messe a disposizione dalle organizzazioni.
Nella fase di classificazione, viene assicurato che i documenti che vengono spediti al classificatore passino attraverso canali sicuri. Questi documenti vengono quindi utilizzati solo ed esclusivamente per l’operazione di classificazione, senza mai essere registrati all’interno dei sistemi Siav, e di loro non rimane alcuna traccia una volta che l’informazione riguardante la loro classe è restituita.